I have been working intensively on building serverless applications with AWS over the past few years. Some projects used serverless architecture with lambda in its core, some used lambda functions only for small parts of the system.
Below I want to share a couple of lessons learned and describe bottlenecks, which you may face while developing even a simple system. This is not a tutorial for absolute beginners. I will not be talking about why serverless approach is good or bad and I expect that you are familiar with AWS, learned about lambda and have played a bit with it.
Overview
A simplified architecture of serverless application may look like this:
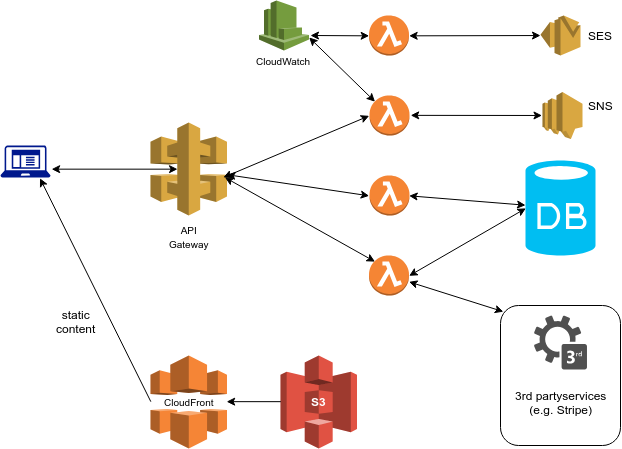
I intentionally omitted Route53, VPC and a couple of other services (which you most likely will need) to keep focus on the core serverless components.
Usually we use S3+CloudFront for all the static content and all the requests go through API Gateway to lambda, which is used as a backend-core. CloudWatch also plays an important role in aggregating logs and in some cases triggers lambda functions at a specific day/time. From lambda we can access a database to save/load the data, SES/SNS to send notifications and multiple 3rd party services.
You can read more details on serverless webapp creation here. Now let’s focus on some issues, which you may face while designing and developing a serverless application.
VPC or no-VPC?
VPC is one of the core services and is used in almost every project, however there are a couple of extra things we need to consider with serverless architecture.
Usually, a database is placed into a private subnet and instance which requires an internet access and database access can be placed into a public subnet. You cannot do it with lambda. Each lambda is assigned a private IP address, but is not assigned any public IP addresses, so you have to place your lambda function into a private subnet. If lambda requires an internet access, you will have to add a NAT Gateway/instance, which costs money and you will end-up paying for what you could get for free in a non-serverless approach.
Another important thing to watch for when using VPC+Lambda combination is the number of available IP addresses in your subnet. And it may not be easy, as you don’t control the number of lambda functions running at the moment. So one of the Lambda Best Practices is: Don’t put your lambda function in a VPC unless you really have to.
RDS and SQL databases in serverless world
SQL databases are not easy to scale. It becomes even more complex in a serverless app, where you don’t control how many lambda you have at any given moment, so your database may quickly become a bottleneck. However even in a simpler scenario, where we don’t expect thousands of lambdas running at the same time, we may face potential problems.
It’s considered good practice to place a heavy initialization code (e.g. connection to the database, loading and applying configuration) out of the lambda handler, because you only want to execute it once instead of loading exactly the same configuration objects on every request.
# This will be run only once for each lambda (when it's created)
config = load_configuration()
# This will be run on every call to lambda function
def handler_name(event, context):
# use configuration object
...
return some_value
Creating a database connection only once in the beginning and reusing it for multiple requests makes sense as it affects performance (in a good way). However with the lambda we will face the following problem: we don't know when to close the connection and the lambda function may be *killed* at any moment. As a result, we may end up with many stale connections.
So, creating a database connection every time the request is received and closing it after the request is handled is not such a bad idea when using RDS + Lambda.
Warming up your lambdas
If your lambda is not used, it will eventually be killed. The good thing is that it all happens automatically, AWS scales it up and down depending on the load, and we don’t have to worry about this.
The bad thing is that, eventually, we may have a situation when there are no running lambdas at the moment. The one will be created as soon as customer triggers a corresponding functionality. The problem with that is lambda initialization may take a couple of seconds, plus some time is required to handle the request. 2018 is not the year when customer should be waiting 5-6 seconds (network delay is not even considered here) for a response from the server. It may hurt your business. The solution is simple: we can create a CloudWatch rule which will trigger the lambda ever X minutes (There are no information on how often exactly the lambda should be triggered to be alive. You may do your own experiments or research, but ~15 min should solve the problem) to keep at least one instance of lambda alive. In the handler we can catch this keep-alive CloudWatch event and return from function immediately.
However we should remember that each call to lambda does affect our budget.
Deployment
Obviously we want an easy automated deployment. Fortunately we have multiple options here:
- CloudFormation/Terraform
- Serverless Framework - wrapper on CloudFormation, which give a very nice experience, has tons of plugins and works across different clouds
- rich API which AWS provides
- apex
Usually we want to have multiple stages: dev, qa, prod and we will need to run different lambda functions in each stage and you can’t have two lambda functions with the same name in the region. I saw very different approaches to solve this problem and support multiple deployment stages:
- different suffixes for API and lambda in the same region
- using different regions
- using different accounts for dev and prod
- lambda versions and aliases & API Gateway stage variables
The last two options are the most convenient in my opinion and probably the most popular.
Lambda configuration
It’s always convenient when your configuration is decoupled from your code. It simplifies many things and we won’t have to redeploy the whole package when everything we want to do is changing log level from Info to Warning.
This is the topic which is discussed often enough during breaks on conferences and meetups. The article Configure your lambda functions like a champ and let your code sail smoothly to Production describes the topic really well. Please, read it, it is worth it.
I will just mention once again, that in your lambda handler you receive two objects: event and context; and you can check what version of lambda was called (to load the corresponding configuration from S3/DynamoDB/etc) using code like this:
alias = context.invoked_function_arn.split(':')[-1]
if alias == 'prod':
...
else:
...
Other
The article is already quite long and I haven’t mentioned even half of what I wanted to say. I will be writing separate blog posts on other serverless topics. For now I just want to mention a couple of important features, which may be useful:
- API Gateway caching - is a great and easy way to offload the lambda function, but remember, that it doesn’t support different parameters in the same request. For example, the two following requests may return the same result when caching is enabled:
GET /v1/products?p1=1&p2=2
GET /v1/products?p1=29&p2=28
- CORS - another piece of WebLogic which we can keep on API Gateway side and it’s quite easy. Let’s never set
Access-Control-Allow-Originto ‘*’ in production unless it’s actually needed - lambda policies - easy to add and it has to be done in a granular level for each alias of your lambda function. If lambda only needs to be called by API Gateway and only by POST request with a unique path, then write a corresponding lambda policy and allow only what is necessary
- Serverless application security is in not in a bad state, but it continues to be a challenge and developer still has to carry about many things, and the most popular one
SQL injectionis still here.